FAQ
PdfGrabber (Windows) : FAQ
Vous trouverez ici des réponses aux questions fréquemment posées concernant notre logiciel « PdfGrabber » (version pour WINDOWS).
Rechercher dans la FAQ
PdfGrabber 8 fonctionne sous Windows 10 uniquement jusqu’à la version 1607 (Creators Update).
Si vous utilisez une version plus récente de Windows 10, vous devez mettre à niveau vers PdfGrabber 9 ou plus récent.
« PixelPlanet PdfPrinter » permet de réduire la taille des fichiers PDF (inclus dans PdfEditor et PdfGrabber). Créez simplement votre PDF à nouveau en l’ouvrant dans Acrobat Reader, puis « imprimez-le » à l’aide de « PixelPlanet PdfPrinter ».
Dans les paramètres d’impression, les options suivantes peuvent être utilisées pour réduire la taille du fichier :
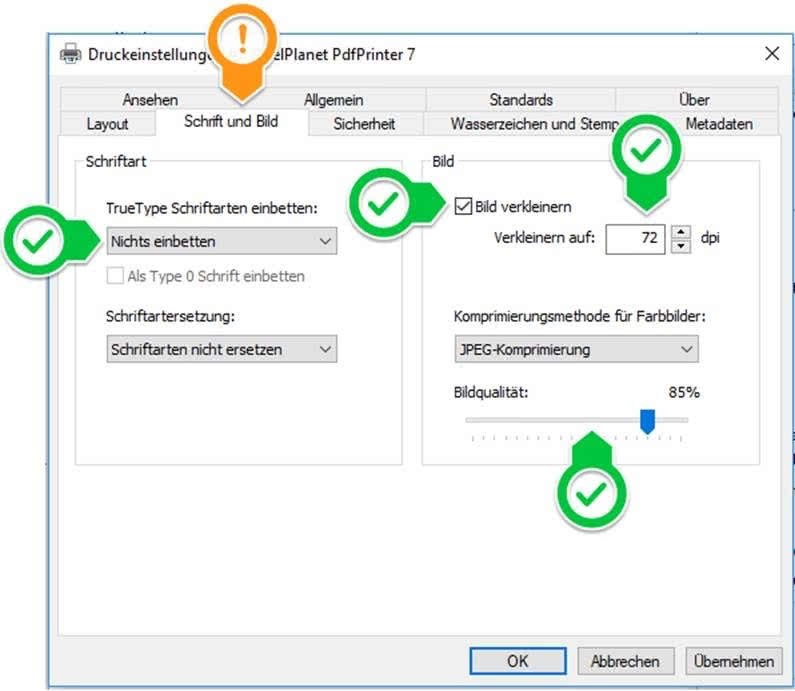
Non. Même si vous disposez d’une licence réseau, l’imprimante PDF PdfPrinter doit toujours être installée localement.
Les packs de langue de la bibliothèque ROC Tesseract sont normalement déposés dans le répertoire « %programdata%\PixelPlanet\Tesseract3_5 ».
Toutefois, ils peuvent également être déposés manuellement dans le répertoire du programme/d’installation:
PdfEditor :
« C:\Program Files (x86)\PixelPlanet\PdfEditor 4\Tesseract3_5\tessdata\ »
PdfGrabber :
« C:\Program Files (x86)\PixelPlanet\PdfGrabber 9\Tesseract3_5\tessdata\ »
Décompressez le contenu du fichier « Packs de langue » (ZIP) correspondant dans le sous-répertoire créé au préalable.
Packs de langue
Afrikaans,
Amharic,
Arabe,
Assamese,
Azerbaijani,
Azerbaijani – Cyrillic,
Belarusian,
Bengali,
Tibetian,
Bosnian,
Bulgarian,
Catalan,
Cebuano,
Czech,
Chinese (Simplified),
Chinese (Traditional),
Cherokee,
Welsh,
Danish,
German,
Dzongkha,
Greek (modern),
English,
English, Middle (1100-1500),
Esperanto,
Estonian,
Basque,
Persian,
Finnish,
French,
Frankish,
Hebrew,
Hindu,
Hungarian,
Indonesian,
Italian,
Japanese,
Korean,
Latvian,
Lithuanian,
Dutch,
Norwegian,
Polish,
Portuguese,
Romanian,
Russian,
Slovak,
Slovene,
Serbian,
Spanish,
Albanian,
Serbian,
Serbian (Latin),
Swedish,
Tagalog,
Thai,
Turkish,
Ukrainian,
Uzbek,
Uzbek (Cyrillic),
Vietnamese,
Yiddish
PdfGrabber a été installé alors qu’un autre utilisateur (disposant des droits d’administrateur) était connecté. Vous avez besoin des données de connexion (mot de passe) de cet utilisateur ou d’un autre utilisateur disposant des droits d’administrateur sur cet ordinateur.
Effectuez maintenant les étapes suivantes pendant que la session de l’utilisateur qui rencontre ce problème est ouverte :
avec un clic droit, ouvrez le menu contextuel du lien PdfGrabber dans le menu « Démarrer ». Dans le menu contextuel, choisissez l’option « Exécuter en tant que… ». Dans la fenêtre suivante, sélectionnez d’abord l’option « Utilisateur suivant », puis saisissez les données d’un utilisateur disposant des droits d’administrateur dans la case à cocher correspondante. Pour cela, vous devez saisir le mot de passe de cet utilisateur.
PdfGrabber démarre :
ouvrez l’entrée de menu « Options – Réglages ». Dans l’onglet « Autres », désactiver les options « Intégration Windows Explorer » et « Intégration Microsoft Office » dans la zone « Plug-ins », puis confirmer en cliquant sur le bouton « Accepter ». Activez ensuite de nouveau les options « Intégration Windows Explorer » et « Intégration Microsoft Office », puis fermez la fenêtre de réglage en cliquant sur le bouton « OK ».
Si le menu « Exécuter en tant que… » n’est pas disponible, il se peut que ce soit à cause du système d’exploitation ou que le menu ait été désactivé à distance dans le réseau par l’administrateur système. Dans les deux cas, veuillez contacter votre administrateur système.
Vérifiez si les objets manquants ne sont pas de simples surfaces remplies sans aucune ligne de contour. Pour cela, répétez l’exportation en activant l’option « Remplissages – Remplir les surfaces ».
Dans le document PDF, l’ensemble des objets qui ressemblent à des lettres/textes sont en réalité des commandes de caractères. Prenons l’exemple d’un « i » :
au lieu de la commande « Exécuter le texte : i », contenue dans le texte source du PDF, les consignes suivantes sont exécutées : « Dessiner un point » et « Dessiner une courte ligne verticale ». Lorsqu’aucune consigne d’exécution de texte n’est précisée dans le document PDF, aucune entité « texte » n’est générée dans le document DXF. Les commandes d’exécution de caractères sont exportées en tant qu’entités « caractère », les commandes d’exécution de textes en tant qu’entités « texte ». La modification des réglages d’exécution du texte n’a aucun effet, tout comme le réglage déterminant qu’aucun texte ne doit être exporté.
Le contenu du document PDF n’est pas une image vectorielle, mais une image intégrée et/ou la page a été scannée. Ceci signifie qu’aucune information concernant les caractères et les lignes, permettant la (re)conversion au format DXF, n’est disponible. Lorsque seules certaines sections manquent, il s’agit souvent de la légende ou du logo du fichier modèle CAO d’un dessin CAO sinon disponible avec des informations concernant les lignes et les caractères. Il est possible d’exporter la page avec le profil « Images – Images contenues » dans le cadre d’un contre-test. Dans la mesure où des images sont alors exportées, les zones concernées ne sont pas exportées au format DXF.
De nombreux documents PDF contiennent des polices intégrées. Toutefois, pour ces polices, l’encodage des caractères est différent, c’est-à-dire que leur affectation a été modifiée (par ex. « ß » devient « a »). À l’exception de cas particuliers, PdfGrabber est en mesure de défaire cet encodage et d’afficher les lettres correctes. Pour cela, il faut néanmoins utiliser la police originale du document PDF pour l’affichage dans le document exporté. Cependant, ceci est impossible en cas d’exportation au format DXF, en raison des restrictions des polices pouvant être utilisées dans ce format. Lors de l’exportation au format DXF, le programme tente, selon les réglages, de recourir à une police de substitution. Ce faisant, le programme ne peut toutefois pas défaire l’encodage.
Comme les éléments de formulaire ne sont pas créés lors de la conversion en Word, vous devez ajouter les textes dans les champs de texte. Ces champs sont simplement insérés à l’endroit souhaité dans le fichier Word.
Pour ajouter un champ de texte sélectionnez la commande « ajouter – champ de texte » dans Word et faites un clic droit avec la souris sur l’emplacement prévu. Après avoir entré le texte vous devez reformater le champ de texte. Pour cela cliquez deux fois sur le bord de celui-ci et dans la page d’enregistrement accédez à « encadrements et bordures », sous « remplissage » cliquez sur « couleur », « pas de remplissage ». Répétez cette manipulation avec « lignes ».
En format PDF, les documents scannés sont représentés par un graphique (image). Pour ces documents vous avez besoin d’un logiciel de reconnaissance de caractères (ROC).
PdfGrabber (Windows) propose les paramètres de lignes de commande suivants à partir de la version Professional :
/LANGID 1031 (allemand)
/LANGID 1033 (anglais)
/LANGID 1036 (français)
/[“nom du fichier”] Exploite le fichier donné avec le dernier profil choisi ou bien le profil actuel.
/profile [« nom du profil »] [« nom du fichier »] Exploite le fichier donné avec le profil correspondant.
/profileid [“Index”]
/SILENT ou /S
Traite le fichier donné en mode silence. PdfGrabber exporte le fichier en arrière-plan et est refermé à la fin.
/close
PdfGrabber exporte le fichier en arrière-plan et est refermé à la fin.
/show
Ouvre les documents convertis une fois que la conversion a réussi.
/pages [« pages à imprimer »] Exporte les pages données ou les groupes de pages, par ex. pages « 1,3-5; 12 ».
/pass [« mot de passe »] Autorise l’entrée d’un mot de passe, lorsque celui-ci est nécessaire pour ouvrir ou bien exporter le fichier PDF.
/output [« répertoire »] Sauvegarde les fichiers exportés dans le répertoire indiqué au lieu du dossier prédéfini par le profil.
/outfilename [« nom du fichier »] Sauvegarde le fichier exporté sous le nom de fichier indiqué. Ainsi, le nom du fichier d’exécution peut être différent de celui du fichier PDF original.
/move [« répertoire »] Déplace le fichier édité dans le répertoire indiqué.
Il est également possible de tester les paramètres avec la version de démonstration, pour cela entrez simplement dans l’invite
c:\Program Files (x86)\PixelPlanet\PdfGrabber 9\PdfGrabber.exe /profile [nom du profil] [nom du fichier]
[nom du profil], remplacez le par le nom de profil désiré (evtl. en « »), [nom du fichier] dans le document à exporter (chemin + nom).PdfGrabber propose une fonction d’exécution au moyen de l’interface COM. La définition d’interface COM se trouve dans le fichier exécutable de PdfGrabber (.exe) et peut être intégrée dans votre environnement informatique par importation de la bibliothèque d’impression.
Ces fonctionnalités ne sont pas disponibles dans la version Standard, par conséquent l’utilisateur final doit acquérir une licence Professional.
Toutes les éditions vous donnent la possibilité d’utiliser la fonction « dossier contrôlé », pour exécuter PdfGrabber à partir d’une application externe. Pour chaque profil un dossier à contrôler par PdfGrabber peut être défini. Aussitôt qu’un nouveau fichier est sauvegardé dans ce classeur, l’exportation démarre et le fichier est ajouté dans votre répertoire de sortie. Les données concernant cette fonction sont disponibles dans les options de profil.
Dans Excel, les options de format affectent la « qualité d’édition ». Au moyen de la règle vous pouvez choisir entre « exact » (nombreuses colonnes) et « bonne exploitation » (peu de colonnes). Les paramètres doivent être modifiés ou adaptés individuellement pour chaque fichier PDF. Nous recommandons de débuter l’exportation avec une valeur moyenne. S’il y a trop de colonnes dans le fichier Excel, choisissez une valeur supérieure (règle vers la droite). En cas de colonnes insuffisantes sélectionnez une valeur inférieure (règle vers la gauche). Effectuez dans ce cas plusieurs tests afin d’obtenir les paramètres adéquats pour le document respectif.
Pour convertir vos documents PDF en RTF ou en Word, vous devez procéder de la façon suivante :
1. Démarrez PdfGrabber et dans la zone supérieure de la fenêtre, sélectionnez le format de sortie souhaité. PdfGrabber vous propose différents formats suffisants pour la plupart des demandes. Selon votre projet choisissez le format « Word/RTF » – « Mise en page identique ». Celle-ci contient tous les paramètres prédéfinis, nécessaires pour une exportation aussi fidèle que possible vers le format RTF ou Word.
2. À présent, sélectionnez « Document source » dans la zone au milieu de la fenêtre. Pour ajouter un document à la liste, cliquez sur « Ajouter ». Dans la boîte de dialogue qui s’affiche sélectionnez le fichier souhaité.
3. Pour terminer, cliquez sur le bouton « Démarrer », afin de commencer le procédé d’exportation. Pendant ce procédé, la fenêtre affichant le statut est visible.
4. Lorsque le procédé d’exportation est terminé, le document exporté s’ouvre dans Word, dans la mesure où ce programme est installé sur votre ordinateur.
Le mauvais affichage du document chez le destinataire est en général provoqué par une police manquante sur le système cible. Pour résoudre le problème, activez sous « Profil — traitement — Format — options-texte enrichi » l’option « Utiliser les polices TrueType ». Veuillez noter que la taille du fichier sera alors augmentée.
Lorsque vous ouvrez des documents exportés avec Microsoft Word, assurez-vous que vous avez choisi dans le menu « aperçu » le mode « mise en page pages » ou « mise en page en ligne ». En mode normal le phénomène décrit peut se produire.
L’exportation de gros fichiers PDF avec beaucoup d’images dure très longtemps. Que puis-je faire ?
Pour exporter les très gros documents PDF, d’énormes ressources sont nécessaires. Par exemples les images dans PDF sont certes comprimées et donc relativement petites, mais pour l’exportation, elles doivent être d’abord décomprimées. Une image en haute résolution peut atteindre 50 MB et plus, ce qui peut entraîner pour beaucoup d’images ou bien de gros documents, une durée de traitement trop longue. Pour résoudre ce problème vous avez plusieurs possibilités :
a) Vérifiez que la mémoire de votre système est suffisante.
b) Désactivez dans les paramètres profil sous « Format – options de format » l’exportation des « images » et des « lignes en image d’arrière-plan », afin de ne pas éditer de graphique et de réduire la taille du fichier.
c) Exportez le document en plusieurs parties (page 1 – 100, page 101 – 200, etc.). Vous pouvez paramétrer la zone de pages souhaitée dans les options profil du registre « zones ».
Assurez-vous que vous utilisez la version actuelle de PdfGrabber. L’exécution de lignes et de cadres n’est proposée qu’à partir de la version 1.0.0.24 pour les profils RTF/Word « Zone de texte » et « Mise en page par tabulateurs ». En option, il est possible d’exporter des lignes et des vecteurs en tant qu’image d’arrière-plan. Pour cela, activez l’option « Lignes en tant qu’image d’arrière-plan » dans les options de profil sous « Format — Options de format ». L’exécution de lignes, de cadres et de vecteurs avec d’autres profils est en partie en préparation. À partir de la version 2.5, les couleurs d’arrière-plan et les cadres peuvent également être exécutés lors de l’exportation native Excel.
Une sortie erronée peut avoir plusieurs causes. Si possible, envoyez le fichier concerné par e-mail à notre support technique. Indiquez dans quel format vous désirez l’exporter et comment nous pouvons vous joindre. Tous les documents reçus sont traités en toute confidentialité et utilisés seulement pour une analyse interne.
Oui, à condition que le mot de passe pour ce fichier soit connu. PdfGrabber fournit un support concernant ce sujet dans le gestionnaire des mots de passe.
Oui. À partir de la version PdfGrabber 3.0 Standard nous fournissons aussi une imprimante virtuelle, qui permet de retransformer les documents convertis en PDF à partir de n’importe quelle application à l’aide d’un pilote d’impression. Exportez les fichiers PDF, effectuez les modifications souhaitées et sauvegardez le fichier de nouveau en PDF.
Vous pouvez commander la version complète dans notre boutique ou auprès de votre vendeur de logiciels. La livraison se fait par téléchargement, c’est-à-dire que vous recevez une clé de connexion par e-mail. Si vous ne souhaitez pas commander par Internet, vous pouvez nous faxer votre commande.
Dans la version de démonstration, des caractères « X » sont ajoutés au hasard dans le texte converti.
Cette limitation n’existe pas dans la version complète de PdfGrabber.
Si vous possédez déjà une licence et que les caractères « X » apparaissent encore, assurez-vous que vous avez activé le logiciel avec le numéro de licence exact.
De plus les graphiques sont édités avec une marque lors de l’exportation.
Cette limitation disparaît dans la version complète, que vous pouvez commander dans notre boutique ou chez votre revendeur.